User login
The language of AI and its applications in health care
AI is a group of nonhuman techniques that utilize automated learning methods to extract information from datasets through generalization, classification, prediction, and association. In other words, AI is the simulation of human intelligence processes by machines. The branches of AI include natural language processing, speech recognition, machine vision, and expert systems. AI can make clinical care more efficient; however, many find its confusing terminology to be a barrier.1 This article provides concise definitions of AI terms and is intended to help physicians better understand how AI methods can be applied to clinical care. The clinical application of natural language processing and machine vision applications are more clinically intuitive than the roles of machine learning algorithms.
Machine learning and algorithms
Machine learning is a branch of AI that uses data and algorithms to mimic human reasoning through classification, pattern recognition, and prediction. Supervised and unsupervised machine-learning algorithms can analyze data and recognize undetected associations and relationships.
Supervised learning involves training models to make predictions using data sets that have correct outcome parameters called labels using predictive fields called features. Machine learning uses iterative analysis including random forest, decision tree, and gradient boosting methods that minimize predictive error metrics (see Table 1). This approach is widely used to improve diagnoses, predict disease progression or exacerbation, and personalize treatment plan modifications.
Supervised machine learning methods can be particularly effective for processing large volumes of medical information to identify patterns and make accurate predictions. In contrast, unsupervised learning techniques can analyze unlabeled data and help clinicians uncover hidden patterns or undetected groupings. Techniques including clustering, exploratory analysis, and anomaly detection are common applications. Both of these machine-learning approaches can be used to extract novel and helpful insights.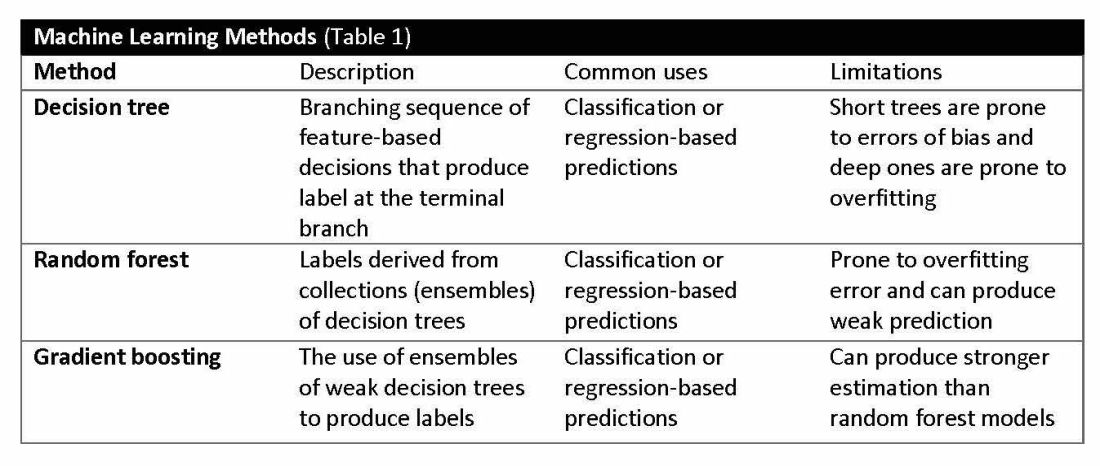
The utility of machine learning analyses depends on the size and accuracy of the available datasets. Small datasets can limit usability, while large datasets require substantial computational power. Predictive models are generated using training datasets and evaluated using separate evaluation datasets. Deep learning models, a subset of machine learning, can automatically readjust themselves to maintain or improve accuracy when analyzing new observations that include accurate labels.
Challenges of algorithms and calibration
Machine learning algorithms vary in complexity and accuracy. For example, a simple logistic regression model using time, date, latitude, and indoor/outdoor location can accurately recommend sunscreen application. This model identifies when solar radiation is high enough to warrant sunscreen use, avoiding unnecessary recommendations during nighttime hours or indoor locations. A more complex model might suffer from model overfitting and inappropriately suggest sunscreen before a tanning salon visit.
Complex machine learning models, like support vector machine (SVM) and decision tree methods, are useful when many features have predictive power. SVMs are useful for small but complex datasets. Features are manipulated in a multidimensional space to maximize the “margins” separating 2 groups. Decision tree analyses are useful when more than 2 groups are being analyzed. SVM and decision tree models can also lose accuracy by data overfitting.
Consider the development of an SVM analysis to predict whether an individual is a fellow or a senior faculty member. One could use high gray hair density feature values to identify senior faculty. When this algorithm is applied to an individual with alopecia, no amount of model adjustment can achieve high levels of discrimination because no hair is present. Rather than overfitting the model by adding more nonpredictive features, individuals with alopecia are analyzed by their own algorithm (tree) that uses the skin wrinkle/solar damage rather than the gray hair density feature.
Decision tree ensemble algorithms like random forest and gradient boosting use feature-based decision trees to process and classify data. Random forests are robust, scalable, and versatile, providing classifications and predictions while protecting against inaccurate data and outliers and have the advantage of being able to handle both categorical and continuous features. Gradient boosting, which uses an ensemble of weak decision trees, often outperforms random forests when individual trees perform only slightly better than random chance. This method incrementally builds the model by optimizing the residual errors of previous trees, leading to more accurate predictions.
In practice, gradient boosting can be used to fine-tune diagnostic models, improving their precision and reliability. A recent example of how gradient boosting of random forest predictions yielded highly accurate predictions for unplanned vasopressor initiation and intubation events 2 to 4 hours before an ICU adult became unstable.2
Assessing the accuracy of algorithms
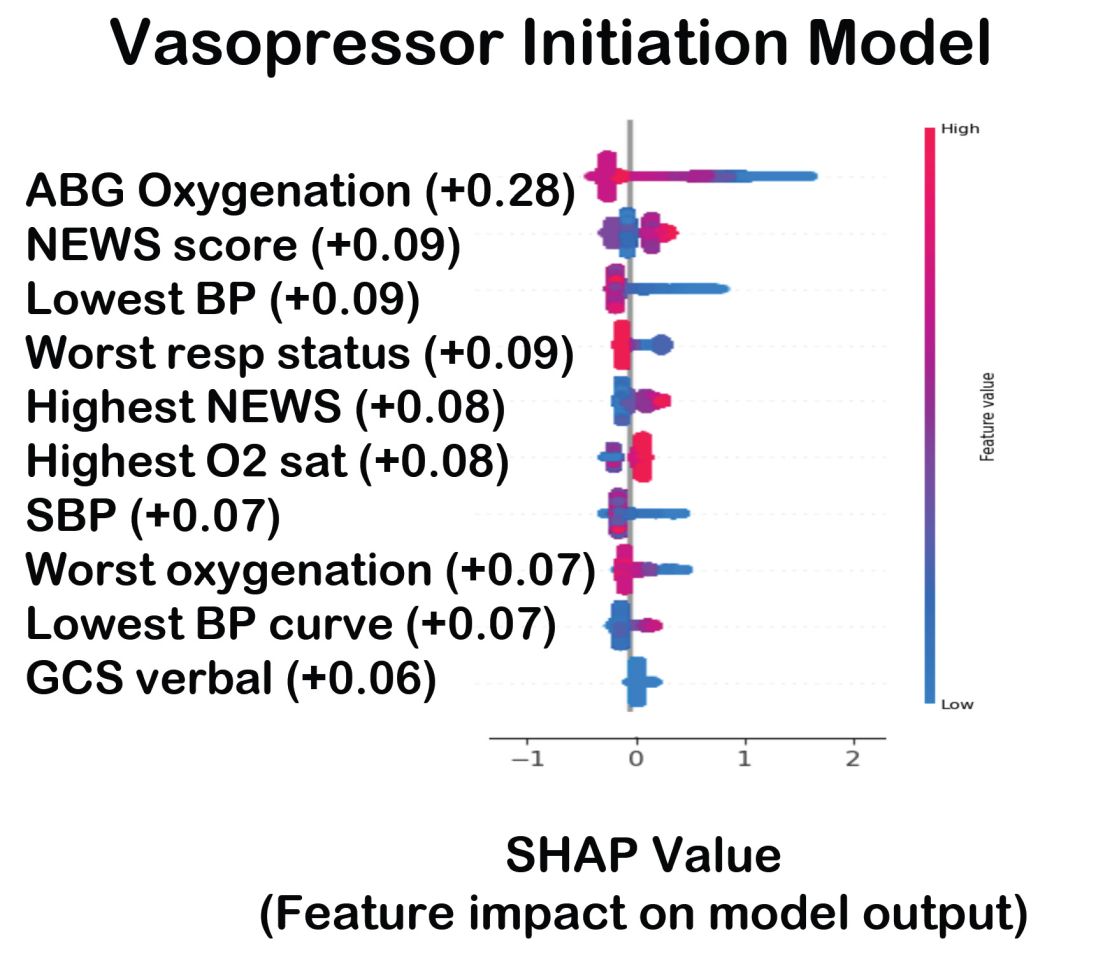
The value of the data set is directly related to the accuracy of its labels. Traditional methods that measure model performance, such as sensitivity, specificity, and predictive values (PPV and NPV), have important limitations. They provide little insight into how a complex model made its prediction. Understanding which individual features drive model accuracy is key to fostering trust in model predictions. This can be done by comparing model output with and without including individual features. The results of all possible combinations are aggregated according to feature importance, which is summarized in the Shapley value for each model feature. Higher values indicate greater relative importance. SHAP plots help identify how much and how often specific features change the model output, presenting values of individual model estimates with and without a specific feature (see Figure 1).
Promoting AI use
AI and machine learning algorithms are coming to patient care. Understanding the language of AI helps caregivers integrate these tools into their practices. The science of AI faces serious challenges. Algorithms must be recalibrated to keep pace as therapies advance, disease prevalence changes, and our population ages. AI must address new challenges as they confront those suffering from respiratory diseases. This resource encourages clinicians with novel approaches by using AI methodologies to advance their development. We can better address future health care needs by promoting the equitable use of AI technologies, especially among socially disadvantaged developers.
References
1. Lilly CM, Soni AV, Dunlap D, et al. Advancing point of care testing by application of machine learning techniques and artificial intelligence. Chest. 2024 (in press).
2. Lilly CM, Kirk D, Pessach IM, et al. Application of machine learning models to biomedical and information system signals from critically ill adults. Chest. 2024;165(5):1139-1148.
AI is a group of nonhuman techniques that utilize automated learning methods to extract information from datasets through generalization, classification, prediction, and association. In other words, AI is the simulation of human intelligence processes by machines. The branches of AI include natural language processing, speech recognition, machine vision, and expert systems. AI can make clinical care more efficient; however, many find its confusing terminology to be a barrier.1 This article provides concise definitions of AI terms and is intended to help physicians better understand how AI methods can be applied to clinical care. The clinical application of natural language processing and machine vision applications are more clinically intuitive than the roles of machine learning algorithms.
Machine learning and algorithms
Machine learning is a branch of AI that uses data and algorithms to mimic human reasoning through classification, pattern recognition, and prediction. Supervised and unsupervised machine-learning algorithms can analyze data and recognize undetected associations and relationships.
Supervised learning involves training models to make predictions using data sets that have correct outcome parameters called labels using predictive fields called features. Machine learning uses iterative analysis including random forest, decision tree, and gradient boosting methods that minimize predictive error metrics (see Table 1). This approach is widely used to improve diagnoses, predict disease progression or exacerbation, and personalize treatment plan modifications.
Supervised machine learning methods can be particularly effective for processing large volumes of medical information to identify patterns and make accurate predictions. In contrast, unsupervised learning techniques can analyze unlabeled data and help clinicians uncover hidden patterns or undetected groupings. Techniques including clustering, exploratory analysis, and anomaly detection are common applications. Both of these machine-learning approaches can be used to extract novel and helpful insights.
The utility of machine learning analyses depends on the size and accuracy of the available datasets. Small datasets can limit usability, while large datasets require substantial computational power. Predictive models are generated using training datasets and evaluated using separate evaluation datasets. Deep learning models, a subset of machine learning, can automatically readjust themselves to maintain or improve accuracy when analyzing new observations that include accurate labels.
Challenges of algorithms and calibration
Machine learning algorithms vary in complexity and accuracy. For example, a simple logistic regression model using time, date, latitude, and indoor/outdoor location can accurately recommend sunscreen application. This model identifies when solar radiation is high enough to warrant sunscreen use, avoiding unnecessary recommendations during nighttime hours or indoor locations. A more complex model might suffer from model overfitting and inappropriately suggest sunscreen before a tanning salon visit.
Complex machine learning models, like support vector machine (SVM) and decision tree methods, are useful when many features have predictive power. SVMs are useful for small but complex datasets. Features are manipulated in a multidimensional space to maximize the “margins” separating 2 groups. Decision tree analyses are useful when more than 2 groups are being analyzed. SVM and decision tree models can also lose accuracy by data overfitting.
Consider the development of an SVM analysis to predict whether an individual is a fellow or a senior faculty member. One could use high gray hair density feature values to identify senior faculty. When this algorithm is applied to an individual with alopecia, no amount of model adjustment can achieve high levels of discrimination because no hair is present. Rather than overfitting the model by adding more nonpredictive features, individuals with alopecia are analyzed by their own algorithm (tree) that uses the skin wrinkle/solar damage rather than the gray hair density feature.
Decision tree ensemble algorithms like random forest and gradient boosting use feature-based decision trees to process and classify data. Random forests are robust, scalable, and versatile, providing classifications and predictions while protecting against inaccurate data and outliers and have the advantage of being able to handle both categorical and continuous features. Gradient boosting, which uses an ensemble of weak decision trees, often outperforms random forests when individual trees perform only slightly better than random chance. This method incrementally builds the model by optimizing the residual errors of previous trees, leading to more accurate predictions.
In practice, gradient boosting can be used to fine-tune diagnostic models, improving their precision and reliability. A recent example of how gradient boosting of random forest predictions yielded highly accurate predictions for unplanned vasopressor initiation and intubation events 2 to 4 hours before an ICU adult became unstable.2
Assessing the accuracy of algorithms
The value of the data set is directly related to the accuracy of its labels. Traditional methods that measure model performance, such as sensitivity, specificity, and predictive values (PPV and NPV), have important limitations. They provide little insight into how a complex model made its prediction. Understanding which individual features drive model accuracy is key to fostering trust in model predictions. This can be done by comparing model output with and without including individual features. The results of all possible combinations are aggregated according to feature importance, which is summarized in the Shapley value for each model feature. Higher values indicate greater relative importance. SHAP plots help identify how much and how often specific features change the model output, presenting values of individual model estimates with and without a specific feature (see Figure 1).
Promoting AI use
AI and machine learning algorithms are coming to patient care. Understanding the language of AI helps caregivers integrate these tools into their practices. The science of AI faces serious challenges. Algorithms must be recalibrated to keep pace as therapies advance, disease prevalence changes, and our population ages. AI must address new challenges as they confront those suffering from respiratory diseases. This resource encourages clinicians with novel approaches by using AI methodologies to advance their development. We can better address future health care needs by promoting the equitable use of AI technologies, especially among socially disadvantaged developers.
References
1. Lilly CM, Soni AV, Dunlap D, et al. Advancing point of care testing by application of machine learning techniques and artificial intelligence. Chest. 2024 (in press).
2. Lilly CM, Kirk D, Pessach IM, et al. Application of machine learning models to biomedical and information system signals from critically ill adults. Chest. 2024;165(5):1139-1148.
AI is a group of nonhuman techniques that utilize automated learning methods to extract information from datasets through generalization, classification, prediction, and association. In other words, AI is the simulation of human intelligence processes by machines. The branches of AI include natural language processing, speech recognition, machine vision, and expert systems. AI can make clinical care more efficient; however, many find its confusing terminology to be a barrier.1 This article provides concise definitions of AI terms and is intended to help physicians better understand how AI methods can be applied to clinical care. The clinical application of natural language processing and machine vision applications are more clinically intuitive than the roles of machine learning algorithms.
Machine learning and algorithms
Machine learning is a branch of AI that uses data and algorithms to mimic human reasoning through classification, pattern recognition, and prediction. Supervised and unsupervised machine-learning algorithms can analyze data and recognize undetected associations and relationships.
Supervised learning involves training models to make predictions using data sets that have correct outcome parameters called labels using predictive fields called features. Machine learning uses iterative analysis including random forest, decision tree, and gradient boosting methods that minimize predictive error metrics (see Table 1). This approach is widely used to improve diagnoses, predict disease progression or exacerbation, and personalize treatment plan modifications.
Supervised machine learning methods can be particularly effective for processing large volumes of medical information to identify patterns and make accurate predictions. In contrast, unsupervised learning techniques can analyze unlabeled data and help clinicians uncover hidden patterns or undetected groupings. Techniques including clustering, exploratory analysis, and anomaly detection are common applications. Both of these machine-learning approaches can be used to extract novel and helpful insights.
The utility of machine learning analyses depends on the size and accuracy of the available datasets. Small datasets can limit usability, while large datasets require substantial computational power. Predictive models are generated using training datasets and evaluated using separate evaluation datasets. Deep learning models, a subset of machine learning, can automatically readjust themselves to maintain or improve accuracy when analyzing new observations that include accurate labels.
Challenges of algorithms and calibration
Machine learning algorithms vary in complexity and accuracy. For example, a simple logistic regression model using time, date, latitude, and indoor/outdoor location can accurately recommend sunscreen application. This model identifies when solar radiation is high enough to warrant sunscreen use, avoiding unnecessary recommendations during nighttime hours or indoor locations. A more complex model might suffer from model overfitting and inappropriately suggest sunscreen before a tanning salon visit.
Complex machine learning models, like support vector machine (SVM) and decision tree methods, are useful when many features have predictive power. SVMs are useful for small but complex datasets. Features are manipulated in a multidimensional space to maximize the “margins” separating 2 groups. Decision tree analyses are useful when more than 2 groups are being analyzed. SVM and decision tree models can also lose accuracy by data overfitting.
Consider the development of an SVM analysis to predict whether an individual is a fellow or a senior faculty member. One could use high gray hair density feature values to identify senior faculty. When this algorithm is applied to an individual with alopecia, no amount of model adjustment can achieve high levels of discrimination because no hair is present. Rather than overfitting the model by adding more nonpredictive features, individuals with alopecia are analyzed by their own algorithm (tree) that uses the skin wrinkle/solar damage rather than the gray hair density feature.
Decision tree ensemble algorithms like random forest and gradient boosting use feature-based decision trees to process and classify data. Random forests are robust, scalable, and versatile, providing classifications and predictions while protecting against inaccurate data and outliers and have the advantage of being able to handle both categorical and continuous features. Gradient boosting, which uses an ensemble of weak decision trees, often outperforms random forests when individual trees perform only slightly better than random chance. This method incrementally builds the model by optimizing the residual errors of previous trees, leading to more accurate predictions.
In practice, gradient boosting can be used to fine-tune diagnostic models, improving their precision and reliability. A recent example of how gradient boosting of random forest predictions yielded highly accurate predictions for unplanned vasopressor initiation and intubation events 2 to 4 hours before an ICU adult became unstable.2
Assessing the accuracy of algorithms
The value of the data set is directly related to the accuracy of its labels. Traditional methods that measure model performance, such as sensitivity, specificity, and predictive values (PPV and NPV), have important limitations. They provide little insight into how a complex model made its prediction. Understanding which individual features drive model accuracy is key to fostering trust in model predictions. This can be done by comparing model output with and without including individual features. The results of all possible combinations are aggregated according to feature importance, which is summarized in the Shapley value for each model feature. Higher values indicate greater relative importance. SHAP plots help identify how much and how often specific features change the model output, presenting values of individual model estimates with and without a specific feature (see Figure 1).
Promoting AI use
AI and machine learning algorithms are coming to patient care. Understanding the language of AI helps caregivers integrate these tools into their practices. The science of AI faces serious challenges. Algorithms must be recalibrated to keep pace as therapies advance, disease prevalence changes, and our population ages. AI must address new challenges as they confront those suffering from respiratory diseases. This resource encourages clinicians with novel approaches by using AI methodologies to advance their development. We can better address future health care needs by promoting the equitable use of AI technologies, especially among socially disadvantaged developers.
References
1. Lilly CM, Soni AV, Dunlap D, et al. Advancing point of care testing by application of machine learning techniques and artificial intelligence. Chest. 2024 (in press).
2. Lilly CM, Kirk D, Pessach IM, et al. Application of machine learning models to biomedical and information system signals from critically ill adults. Chest. 2024;165(5):1139-1148.