User login
Like an upstart quick-draw challenging a grizzled gunslinger, preprint servers are muscling in on the once-exclusive territory of scientific journals.
These online venues sidestep the time-honored but lengthy peer-review process in favor of instant data dissemination. By directly posting unreviewed papers, authors escape the months-long drudgery of peer review, stake an immediate claim on new ideas, and connect instantly with like-minded scientists whose feedback can mold this new idea into a sound scientific contribution.
“The caveat, of course, is that it may be crap.”
That’s the unvarnished truth of preprint publishing, said John Inglis, PhD – and he should know. As the cofounder of Cold Spring Harbor Laboratory’s bioRxiv, the largest-to-date preprint server for the biological sciences, he gives equal billing to both the lofty and the low, and lets them soar or sink by their own merit.
And many of them do soar, Dr. Inglis said. Of the more than 20,000 papers published since bioRxiv’s modest beginning in 2013, slightly more than 60% have gone on to peer-reviewed publication. The four most prolific sources of bioRxiv preprints are the research powerhouses of Stanford, Cambridge, Oxford, and Harvard. The twitterverse is virtually awash with #bioRxiv tags, which alert bioRxiv’s 18,000 followers to new papers in any of 27 subject areas. “We gave up counting 2 years ago, when we reached 100,000,” Dr. Inglis said.
BioRxiv, pronounced “bioarchive,” may be the largest preprint server for the biological sciences, but it’s not the only one. The Center for Open Science has created a preprint server search engine, which lists 25 such servers, a number of them in the life sciences.
PeerJ Preprints also offers a home for unreviewed papers, accepting “drafts of an article, abstract, or poster that has not yet been peer reviewed for formal publication.” Authors can submit a draft, incomplete, or final version, which can be online within 24 hours.
The bioRxiv model is coming to medicine, too. A new preprint server – to be called medRxiv – is expected to launch later in 2018 and will accept a wide range of papers on health and medicine, including clinical trial results.

Brand new or rebrand?
Preprint – or at least the concept of it – is nothing new, Dr. Inglis said. It’s simply the extension into the digital space of something that has been happening for many decades in the physical space.
Scientists have always written drafts of their papers and sent them out to friends and colleagues for feedback before unveiling them publicly. In the early 1990s, UC Berkeley astrophysicist Joanne Cohn began emailing unreviewed physics papers to colleagues. Within a couple of years, physicist Paul Ginsparg, PhD, of Cornell University, created a central repository for these papers at the Los Alamos National Laboratory. This repository became aRxiv, a central component of communication in the physical sciences, and the progenitor of the preprint servers now in existence.
The biological sciences were far behind this curve of open sharing, Dr. Inglis said. “I think some biologists were always aware of aRxiv and intrigued by it, but most were unconvinced that the habits and behaviors of research biologists would support a similar process.”
The competition inherent in research biology was likely a large driver of that lag. “Biological experiments are complicated, it takes a long time for ideas to evolve and results to arrive, and people are possessive of their data and ideas. They have always shared information through conferences, but there was a lot of hesitation about making this information available in an uncontrolled way, beyond the audiences at those meetings,” he said.
[polldaddy:9970002]
Nature Publishing Group first floated the preprint notion among biologists in 2006, with Nature Precedings. It published more than 2,000 papers before folding, rather suddenly, in 2012. A publisher’s statement simply said that the effort was “unsustainable as originally conceived.”
Commentators suspected the model was a financial bust, and indeed, preprint servers aren’t money machines. BioRxiv, proudly not for profit, was founded with financial support from Cold Spring Harbor Laboratory and survives largely on private grants. In April 2017, it received a grant for an undisclosed amount from the Chan Zuckerberg Initiative, established by Facebook founder Mark Zuckerberg and his wife, Priscilla Chan.
Who’s minding the data?
The screening process at bioRxiv is minimal, Dr. Inglis said. An in-house staff checks each paper for obvious flaws, like plagiarism, irrelevance, unacceptable article type, and offensive language. Then they’re sent out to a committee of affiliate scientists, which confirms that the manuscript is a research paper and that it contains science, without judging the quality of that science. Papers aren’t edited before being posted online.
Each bioRxiv paper gets a DOI link, and appears with the following disclaimer detailing the risks inherent in reading “unrefereed” science: “Because [peer review] can be lengthy, authors use the bioRxiv service to make their manuscripts available as ‘preprints’ before peer review, allowing other scientists to see, discuss, and comment on the findings immediately. Readers should therefore be aware that articles on bioRxiv have not been finalized by authors, might contain errors, and report information that has not yet been accepted or endorsed in any way by the scientific or medical community.”
From biology to medicine
The bioRxiv team is poised to jump into a different pool now – medical science. Although the launch date isn’t firm yet, medRxiv will go live sometime very soon, Dr. Inglis said. It’s a proposed partnership between Cold Spring Harbor Laboratory, the Yale-based YODA Project (Yale University Open Data Access Project), and BMJ. The medRxiv papers, like those posted to bioRxiv, will be screened but not peer reviewed or scrutinized for trial design, methodology, or interpretation of results.
The benefits of medRxiv will be more rapid communication of research results, increased opportunities for collaboration, the sharing of hard-to-publish outputs like quality innovations in health care, and greater transparency of clinical trials data, Dr. Inglis said. Despite this, he expects the same kind of push-back bioRxiv initially encountered, at least in the beginning.
“I expect we will be turning the clock back 5 years and find a lot of people who think this is potentially a bad thing, a risk that poor information or misinformation is going to be disseminated to a wider audience, which is exactly what we heard about bioRxiv,” he said. “But we hope that when medRxiv launches, it will demonstrate the same kind of gradual acceptance as people get more and more familiar with the preprint platform.”
The founders intend to build into the server policies to mitigate the risk from medically relevant information that hasn’t been peer reviewed, such as not accepting case studies or editorials and opinion pieces, he added.
While many find the preprint disclaimer acceptable on papers that have no immediate clinical impact, there is concern about applying it to papers that discuss patient treatment.
Howard Bauchner, MD, JAMA’s editor in chief, addressed it in an editorial published in September 2017. Although not explicitly directed at bioRxiv, Dr. Bauchner took a firm stance against shortcutting the evaluation of evidence that is often years in the making.
“New interest in preprint servers in clinical medicine increases the likelihood of premature dissemination and public consumption of clinical research findings prior to rigorous evaluation and peer review,” Dr. Bauchner wrote. “For most articles, public consumption of research findings prior to peer review will have little influence on health, but for some articles, the effect could be devastating for some patients if the results made public prior to peer review are wrong or incorrectly interpreted.”
Dr. Bauchner did not overstate the potential influence of unvetted science, as a January 2018 bioRxiv study on CRISPR gene editing clearly demonstrated. The paper by Carsten Charlesworth, a doctoral student at Stanford (Calif.) University, found that up to 79% of humans could already be immune to Crispr-Cas9, the gene-editing protein derived from Staphylococcus aureus and S. pyogenes. More than science geeks were reading: The report initially sent CRISPR stocks tumbling.
Aaron D. Viny, MD, is in general a hesitant fan of bioRxiv’s preprint platform. But he raised an eyebrow when he learned about medRxiv.
“The only pressure that I can see in regulating these reports is social media,” said Dr. Viny, a hematologic oncologist at Memorial Sloan Kettering, in New York. “The fear is that it will be misused in two different realms. The most dangerous and worrisome, of course, is for patients using the data to influence their care plan, when the data haven’t been vetted appropriately. But secondarily, how could it influence the economics of clinical trials? There is no shortage of hedge fund managers in biotech. These data could misinform a consultant who might know the area in a way that artificially exploits early research data. Could that permit someone to submit disingenuous data to manipulate the stock of a given pharmaceutical company? I don’t know how you police that kind of thing.”
Who’s loving it – and why?
There are plenty of reasons to support a thriving preprint community, said Jessica Polka, PhD, director of ASAPbio, (Accelerating Science and Publication in biology), a group that bills itself as a scientist-driven initiative to promote the productive use of preprints in the life sciences.
“Preprinting complements traditional journal publishing by allowing researchers to rapidly communicate their findings to the scientific community,” she said. “This, in turn, provides them with opportunities for earlier and broader feedback and a way to transparently demonstrate progress on a project. More importantly, the whole community benefits by having earlier access to research findings, which can accelerate the pace of discovery.”
The disclosures applied to every preprint paper are the publisher’s way of assuring this same awareness, she said. And preprints do need to be approached with some skepticism, as should peer-reviewed literature.
“The veracity of published papers is not always a given. An example is the 1998 vaccine paper [published in the Lancet] by Dr. Andrew Wakefield,” which launched the antivaccine movement. “But the answer to problems of reliability is to provide more information about the research and how it has been verified and evaluated, not less information. For example, confirmation bias can make it difficult to refute work that has been published. The current incentives for publishing negative results in a journal are not strong enough to reveal all of the information that could be useful to other researchers, but preprinting reduces the barrier to sharing negative results,” she said.
Swimming up the (main)stream
Universal peer-reviewed acceptance of preprints isn’t a done deal, Dr. Polka said. Journals are tussling with how to handle these papers. The Lancet clearly states that preprints don’t constitute prior publication and are welcome. The New England Journal of Medicine offers an uncontestable “no way.”
JAMA discourages submitting preprints, and will consider one only if the submitted version offers “meaningful new information” above what the preprint disseminated.
Cell Press has a slightly different take. They will consider papers previously posted on preprint services, but the policy applies only to the original submitted version of the paper. “We do not support posting of revisions that respond to editorial input and peer review or the final published version to preprint servers,” the policy notes.
In an interview, Deborah Sweet, PhD, the group’s vice president of editorial, elaborated on the policy. “In our view, one of the most important purposes of preprint posting is to gather feedback from the scientific community before a formal submission to a journal,” she said. “The ‘original submission’ term in our guidelines refers to the first version of the paper submitted to [Cell Press], which could include revisions made in response to community feedback on a preprint. After formal submission, we think it is most appropriate to incorporate and represent the value of the editorial and peer-review evaluation process in the final published journal article so that is clearly identifiable as the version of record.”
bioRxiv has made substantial inroads with dozens of other peer-reviewed journals. More than 100 – including a number of publications by EMBO Press and PLOS (Public Library of Science) – participate in bioRxiv’s B2J (BioRxiv-to-journal) direct-submission program.
With a few clicks, authors can transmit their bioRxiv manuscript files directly to these journals, without having to prepare separate submissions, Dr. Sweet said. Last year, Cell Press added two publications – Cell Reports and Structure – to the B2J program. “Once the paper is sent, it moves behind the scenes to the journal system and reappears as a formal submission,” she said. “In our process, before transferring the paper to the journal editors, authors have a chance to update the files (for example, to add a cover letter) and answer the standard questions that we ask, including ones about reviewer suggestions and exclusion requests. Once that step is done, the paper is handed over to the editorial team, and it’s ready to go for consideration in the same way as any other submission.”
Who’s reading?
Regardless of whether peer-review journals grant them legitimacy, preprints are getting a lot of views. A recent research letter, published in JAMA, looked at readership and online attention in 7,750 preprints posted from November 2013 to January 2017.
Primary author Stylianos Serghiou then selected 776 papers that had first appeared in bioRxiv, and matched them with 3,647 peer-reviewed articles lacking preprint exposure. He examined several publishing metrics for the papers, including views and downloads, citations in other sources, and Altmetric scores.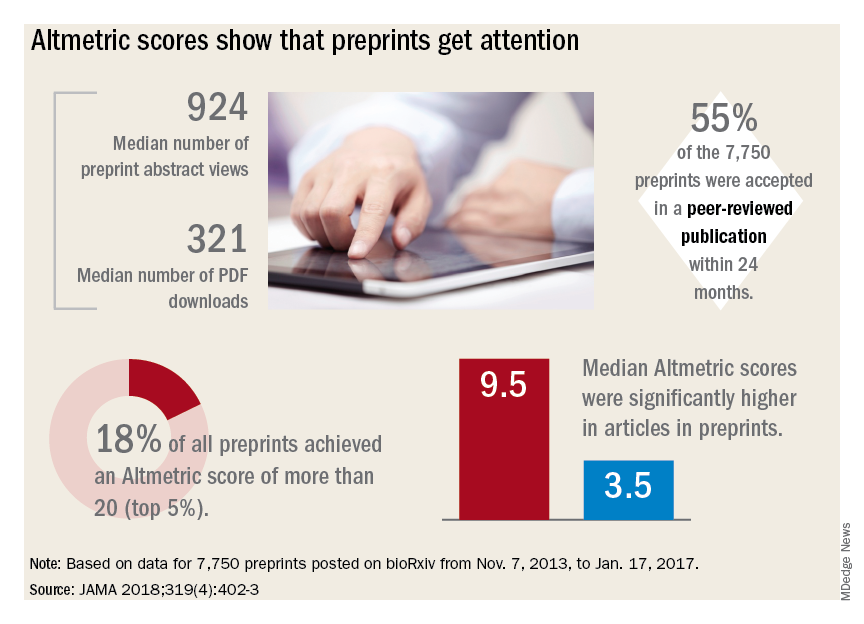
Altmetric tracks digital attention to scientific papers: Wikipedia citations, mentions in policy documents, blog discussions, and social media mentions including Facebook, Reddit, and Twitter. An Altmetric “attention score” of more than 20 corresponds to articles in the top 5% of readership, he said in an interview.
“Almost one in five of the bioRxiv preprints were getting these very high Almetric scores – much higher scores than articles that had no preprint posting,” Mr. Serghiou said in an interview.
Other findings include:
- The median number of preprint abstract views was 924, and the median number of PDF downloads was 321.
- In total, 18% of the preprints achieved an Altmetric score of more than 20.
- Of 7,750 preprints, 55% were accepted in a peer-reviewed publication within 24 months.
- Altmetric scores were significantly higher in articles in preprints (median 9.5 vs. 3.5).
The differences are probably related, at least in part, to the digital media savvy of preprint authors, Mr. Serghiou suggested. “We speculate that people who publish in bioRxiv may be more familiar with social media methods of making others aware of their work. They tend to be very good at using platforms like Twitter and Facebook to promote their results.”
Despite the high exposure scores, only 10% of bioRxiv articles get any posted comments or feedback – a key raison d’être for using a preprint service.
“Ten percent doesn’t sound like a very robust [feedback], but most journal articles get no comments whatsoever,” Dr. Inglis said. “And if they do, especially on the weekly magazines of science, comments may be from someone who has an ax to grind, or who doesn’t know much about the subject.”
What isn’t measured, in either volume or import, is the private communication a preprint engenders, Dr. Inglis said. “Feedback comes directly and privately to the author through email or at meetings or on the phone. We hear time and again that authors get hundreds of downloads after posting, and receive numerous contacts from colleagues who want to know more, to point out weaknesses, or request collaborations. These are the advantages we see from this potentially anxiety-provoking process of putting a manuscript out that has not been approved for publication. The entire purpose is to accelerate the speed of research by accelerating the speed of communication.”
Dr. Inglis, Dr. Sweet, and Dr. Polka are all employees of their respective companies. Dr. Viny and Mr. Serghiou both reported having no financial disclosures relevant to this article.
It’s another beautiful day on the upper east side of Manhattan. The sun shines through the window shades, my 2-year-old daughter sings to herself as she wakes up, my wife has just returned from an early-morning workout – all is right as rain.
My phone buzzes. My stomach clenches. It buzzes again. My Twitter alerts are here. I dread this part of my morning ritual – finding out if I’ve been scooped overnight by the massive inflow of scientific manuscripts reported to me by my army of scientific literature–searching Twitter bots.
But this massive data dump now has a #fakenews problem. It’s not Russian election meddling, it’s open source “preprint” publications. Nearly half of my morning list of Twitter alerts now are sourced from the latest uploads to bioRxiv. BioRxiv is an online site run by scientists at Cold Spring Harbor Laboratory and is composed of posting manuscripts without undergoing a peer-review process. Now, most commonly, these manuscripts are concurrently under review in the bona fide peer-review process elsewhere, but unrevised, they are uploaded directly for public consumption.
There was one recent tweet that highlighted some interesting logistical considerations for bioRxiv manuscripts in the peer-review process. The tweet from an unnamed laboratory complains that a peer reviewer is displeased with the authors citing their own bioRxiv paper, while the tweeter contends that all referenced information, online or otherwise, must be cited. Moreover, the reviewer brings up an accusation of self-plagiarism as the submitted manuscript is identical to the one on bioRxiv. While the latter just seems like a misunderstanding of the bioRxiv platform, the former is a really interesting question of whether bioRxiv represents data that can/should be referenced.
Proponents of the platform are excited that data is accessible sooner, that one’s latest and greatest scientific finding can be “scoop proof” by getting it online and marking one’s territory. Naysayers contend that, without peer review, the work cannot truly be part of the scientific literature and should be taken with great caution.
There is undoubtedly danger. Online media sources Gizmodo and the Motley Fool both reported that a January 2018 bioRxiv preprint resulted in a nearly 20% drop in stock prices of CRISPR biotechnology firms Editas Medicine and Intellia Therapeutics. The manuscript warned of the potential immunogenicity of CRISPR, suggesting that preexisting antibodies might limit its clinical application. Far more cynically, this highlights how a stock price could theoretically be artificially manipulated through preprint data.
The preprint is an open market response to the long, arduous process that peer review has become, but undoubtedly, peer review is an essential part of how we maintain transparency and accountability in science and medicine. It remains to be seen exactly how journal editors intend to use bioRxiv submissions in the appraisal of “novelty.”
How will the scientific community vet and referee the works, and will the title and conclusions of a scientifically flawed work permeate misleading information into the field and lay public? Would you let it influence your research or clinical practice? We will be finding out one tweet at a time.
Aaron D. Viny, MD, is with the Memorial Sloan Kettering Cancer Center, N.Y., where he is a clinical instructor, is on the staff of the leukemia service, and is a clinical researcher in the Ross Levine Lab. He reported having no relevant financial disclosures. Contact him on Twitter @TheDoctorIsVin.
It’s another beautiful day on the upper east side of Manhattan. The sun shines through the window shades, my 2-year-old daughter sings to herself as she wakes up, my wife has just returned from an early-morning workout – all is right as rain.
My phone buzzes. My stomach clenches. It buzzes again. My Twitter alerts are here. I dread this part of my morning ritual – finding out if I’ve been scooped overnight by the massive inflow of scientific manuscripts reported to me by my army of scientific literature–searching Twitter bots.
But this massive data dump now has a #fakenews problem. It’s not Russian election meddling, it’s open source “preprint” publications. Nearly half of my morning list of Twitter alerts now are sourced from the latest uploads to bioRxiv. BioRxiv is an online site run by scientists at Cold Spring Harbor Laboratory and is composed of posting manuscripts without undergoing a peer-review process. Now, most commonly, these manuscripts are concurrently under review in the bona fide peer-review process elsewhere, but unrevised, they are uploaded directly for public consumption.
There was one recent tweet that highlighted some interesting logistical considerations for bioRxiv manuscripts in the peer-review process. The tweet from an unnamed laboratory complains that a peer reviewer is displeased with the authors citing their own bioRxiv paper, while the tweeter contends that all referenced information, online or otherwise, must be cited. Moreover, the reviewer brings up an accusation of self-plagiarism as the submitted manuscript is identical to the one on bioRxiv. While the latter just seems like a misunderstanding of the bioRxiv platform, the former is a really interesting question of whether bioRxiv represents data that can/should be referenced.
Proponents of the platform are excited that data is accessible sooner, that one’s latest and greatest scientific finding can be “scoop proof” by getting it online and marking one’s territory. Naysayers contend that, without peer review, the work cannot truly be part of the scientific literature and should be taken with great caution.
There is undoubtedly danger. Online media sources Gizmodo and the Motley Fool both reported that a January 2018 bioRxiv preprint resulted in a nearly 20% drop in stock prices of CRISPR biotechnology firms Editas Medicine and Intellia Therapeutics. The manuscript warned of the potential immunogenicity of CRISPR, suggesting that preexisting antibodies might limit its clinical application. Far more cynically, this highlights how a stock price could theoretically be artificially manipulated through preprint data.
The preprint is an open market response to the long, arduous process that peer review has become, but undoubtedly, peer review is an essential part of how we maintain transparency and accountability in science and medicine. It remains to be seen exactly how journal editors intend to use bioRxiv submissions in the appraisal of “novelty.”
How will the scientific community vet and referee the works, and will the title and conclusions of a scientifically flawed work permeate misleading information into the field and lay public? Would you let it influence your research or clinical practice? We will be finding out one tweet at a time.
Aaron D. Viny, MD, is with the Memorial Sloan Kettering Cancer Center, N.Y., where he is a clinical instructor, is on the staff of the leukemia service, and is a clinical researcher in the Ross Levine Lab. He reported having no relevant financial disclosures. Contact him on Twitter @TheDoctorIsVin.
It’s another beautiful day on the upper east side of Manhattan. The sun shines through the window shades, my 2-year-old daughter sings to herself as she wakes up, my wife has just returned from an early-morning workout – all is right as rain.
My phone buzzes. My stomach clenches. It buzzes again. My Twitter alerts are here. I dread this part of my morning ritual – finding out if I’ve been scooped overnight by the massive inflow of scientific manuscripts reported to me by my army of scientific literature–searching Twitter bots.
But this massive data dump now has a #fakenews problem. It’s not Russian election meddling, it’s open source “preprint” publications. Nearly half of my morning list of Twitter alerts now are sourced from the latest uploads to bioRxiv. BioRxiv is an online site run by scientists at Cold Spring Harbor Laboratory and is composed of posting manuscripts without undergoing a peer-review process. Now, most commonly, these manuscripts are concurrently under review in the bona fide peer-review process elsewhere, but unrevised, they are uploaded directly for public consumption.
There was one recent tweet that highlighted some interesting logistical considerations for bioRxiv manuscripts in the peer-review process. The tweet from an unnamed laboratory complains that a peer reviewer is displeased with the authors citing their own bioRxiv paper, while the tweeter contends that all referenced information, online or otherwise, must be cited. Moreover, the reviewer brings up an accusation of self-plagiarism as the submitted manuscript is identical to the one on bioRxiv. While the latter just seems like a misunderstanding of the bioRxiv platform, the former is a really interesting question of whether bioRxiv represents data that can/should be referenced.
Proponents of the platform are excited that data is accessible sooner, that one’s latest and greatest scientific finding can be “scoop proof” by getting it online and marking one’s territory. Naysayers contend that, without peer review, the work cannot truly be part of the scientific literature and should be taken with great caution.
There is undoubtedly danger. Online media sources Gizmodo and the Motley Fool both reported that a January 2018 bioRxiv preprint resulted in a nearly 20% drop in stock prices of CRISPR biotechnology firms Editas Medicine and Intellia Therapeutics. The manuscript warned of the potential immunogenicity of CRISPR, suggesting that preexisting antibodies might limit its clinical application. Far more cynically, this highlights how a stock price could theoretically be artificially manipulated through preprint data.
The preprint is an open market response to the long, arduous process that peer review has become, but undoubtedly, peer review is an essential part of how we maintain transparency and accountability in science and medicine. It remains to be seen exactly how journal editors intend to use bioRxiv submissions in the appraisal of “novelty.”
How will the scientific community vet and referee the works, and will the title and conclusions of a scientifically flawed work permeate misleading information into the field and lay public? Would you let it influence your research or clinical practice? We will be finding out one tweet at a time.
Aaron D. Viny, MD, is with the Memorial Sloan Kettering Cancer Center, N.Y., where he is a clinical instructor, is on the staff of the leukemia service, and is a clinical researcher in the Ross Levine Lab. He reported having no relevant financial disclosures. Contact him on Twitter @TheDoctorIsVin.
Like an upstart quick-draw challenging a grizzled gunslinger, preprint servers are muscling in on the once-exclusive territory of scientific journals.
These online venues sidestep the time-honored but lengthy peer-review process in favor of instant data dissemination. By directly posting unreviewed papers, authors escape the months-long drudgery of peer review, stake an immediate claim on new ideas, and connect instantly with like-minded scientists whose feedback can mold this new idea into a sound scientific contribution.
“The caveat, of course, is that it may be crap.”
That’s the unvarnished truth of preprint publishing, said John Inglis, PhD – and he should know. As the cofounder of Cold Spring Harbor Laboratory’s bioRxiv, the largest-to-date preprint server for the biological sciences, he gives equal billing to both the lofty and the low, and lets them soar or sink by their own merit.
And many of them do soar, Dr. Inglis said. Of the more than 20,000 papers published since bioRxiv’s modest beginning in 2013, slightly more than 60% have gone on to peer-reviewed publication. The four most prolific sources of bioRxiv preprints are the research powerhouses of Stanford, Cambridge, Oxford, and Harvard. The twitterverse is virtually awash with #bioRxiv tags, which alert bioRxiv’s 18,000 followers to new papers in any of 27 subject areas. “We gave up counting 2 years ago, when we reached 100,000,” Dr. Inglis said.
BioRxiv, pronounced “bioarchive,” may be the largest preprint server for the biological sciences, but it’s not the only one. The Center for Open Science has created a preprint server search engine, which lists 25 such servers, a number of them in the life sciences.
PeerJ Preprints also offers a home for unreviewed papers, accepting “drafts of an article, abstract, or poster that has not yet been peer reviewed for formal publication.” Authors can submit a draft, incomplete, or final version, which can be online within 24 hours.
The bioRxiv model is coming to medicine, too. A new preprint server – to be called medRxiv – is expected to launch later in 2018 and will accept a wide range of papers on health and medicine, including clinical trial results.
Brand new or rebrand?
Preprint – or at least the concept of it – is nothing new, Dr. Inglis said. It’s simply the extension into the digital space of something that has been happening for many decades in the physical space.
Scientists have always written drafts of their papers and sent them out to friends and colleagues for feedback before unveiling them publicly. In the early 1990s, UC Berkeley astrophysicist Joanne Cohn began emailing unreviewed physics papers to colleagues. Within a couple of years, physicist Paul Ginsparg, PhD, of Cornell University, created a central repository for these papers at the Los Alamos National Laboratory. This repository became aRxiv, a central component of communication in the physical sciences, and the progenitor of the preprint servers now in existence.
The biological sciences were far behind this curve of open sharing, Dr. Inglis said. “I think some biologists were always aware of aRxiv and intrigued by it, but most were unconvinced that the habits and behaviors of research biologists would support a similar process.”
The competition inherent in research biology was likely a large driver of that lag. “Biological experiments are complicated, it takes a long time for ideas to evolve and results to arrive, and people are possessive of their data and ideas. They have always shared information through conferences, but there was a lot of hesitation about making this information available in an uncontrolled way, beyond the audiences at those meetings,” he said.
[polldaddy:9970002]
Nature Publishing Group first floated the preprint notion among biologists in 2006, with Nature Precedings. It published more than 2,000 papers before folding, rather suddenly, in 2012. A publisher’s statement simply said that the effort was “unsustainable as originally conceived.”
Commentators suspected the model was a financial bust, and indeed, preprint servers aren’t money machines. BioRxiv, proudly not for profit, was founded with financial support from Cold Spring Harbor Laboratory and survives largely on private grants. In April 2017, it received a grant for an undisclosed amount from the Chan Zuckerberg Initiative, established by Facebook founder Mark Zuckerberg and his wife, Priscilla Chan.
Who’s minding the data?
The screening process at bioRxiv is minimal, Dr. Inglis said. An in-house staff checks each paper for obvious flaws, like plagiarism, irrelevance, unacceptable article type, and offensive language. Then they’re sent out to a committee of affiliate scientists, which confirms that the manuscript is a research paper and that it contains science, without judging the quality of that science. Papers aren’t edited before being posted online.
Each bioRxiv paper gets a DOI link, and appears with the following disclaimer detailing the risks inherent in reading “unrefereed” science: “Because [peer review] can be lengthy, authors use the bioRxiv service to make their manuscripts available as ‘preprints’ before peer review, allowing other scientists to see, discuss, and comment on the findings immediately. Readers should therefore be aware that articles on bioRxiv have not been finalized by authors, might contain errors, and report information that has not yet been accepted or endorsed in any way by the scientific or medical community.”
From biology to medicine
The bioRxiv team is poised to jump into a different pool now – medical science. Although the launch date isn’t firm yet, medRxiv will go live sometime very soon, Dr. Inglis said. It’s a proposed partnership between Cold Spring Harbor Laboratory, the Yale-based YODA Project (Yale University Open Data Access Project), and BMJ. The medRxiv papers, like those posted to bioRxiv, will be screened but not peer reviewed or scrutinized for trial design, methodology, or interpretation of results.
The benefits of medRxiv will be more rapid communication of research results, increased opportunities for collaboration, the sharing of hard-to-publish outputs like quality innovations in health care, and greater transparency of clinical trials data, Dr. Inglis said. Despite this, he expects the same kind of push-back bioRxiv initially encountered, at least in the beginning.
“I expect we will be turning the clock back 5 years and find a lot of people who think this is potentially a bad thing, a risk that poor information or misinformation is going to be disseminated to a wider audience, which is exactly what we heard about bioRxiv,” he said. “But we hope that when medRxiv launches, it will demonstrate the same kind of gradual acceptance as people get more and more familiar with the preprint platform.”
The founders intend to build into the server policies to mitigate the risk from medically relevant information that hasn’t been peer reviewed, such as not accepting case studies or editorials and opinion pieces, he added.
While many find the preprint disclaimer acceptable on papers that have no immediate clinical impact, there is concern about applying it to papers that discuss patient treatment.
Howard Bauchner, MD, JAMA’s editor in chief, addressed it in an editorial published in September 2017. Although not explicitly directed at bioRxiv, Dr. Bauchner took a firm stance against shortcutting the evaluation of evidence that is often years in the making.
“New interest in preprint servers in clinical medicine increases the likelihood of premature dissemination and public consumption of clinical research findings prior to rigorous evaluation and peer review,” Dr. Bauchner wrote. “For most articles, public consumption of research findings prior to peer review will have little influence on health, but for some articles, the effect could be devastating for some patients if the results made public prior to peer review are wrong or incorrectly interpreted.”
Dr. Bauchner did not overstate the potential influence of unvetted science, as a January 2018 bioRxiv study on CRISPR gene editing clearly demonstrated. The paper by Carsten Charlesworth, a doctoral student at Stanford (Calif.) University, found that up to 79% of humans could already be immune to Crispr-Cas9, the gene-editing protein derived from Staphylococcus aureus and S. pyogenes. More than science geeks were reading: The report initially sent CRISPR stocks tumbling.
Aaron D. Viny, MD, is in general a hesitant fan of bioRxiv’s preprint platform. But he raised an eyebrow when he learned about medRxiv.
“The only pressure that I can see in regulating these reports is social media,” said Dr. Viny, a hematologic oncologist at Memorial Sloan Kettering, in New York. “The fear is that it will be misused in two different realms. The most dangerous and worrisome, of course, is for patients using the data to influence their care plan, when the data haven’t been vetted appropriately. But secondarily, how could it influence the economics of clinical trials? There is no shortage of hedge fund managers in biotech. These data could misinform a consultant who might know the area in a way that artificially exploits early research data. Could that permit someone to submit disingenuous data to manipulate the stock of a given pharmaceutical company? I don’t know how you police that kind of thing.”
Who’s loving it – and why?
There are plenty of reasons to support a thriving preprint community, said Jessica Polka, PhD, director of ASAPbio, (Accelerating Science and Publication in biology), a group that bills itself as a scientist-driven initiative to promote the productive use of preprints in the life sciences.
“Preprinting complements traditional journal publishing by allowing researchers to rapidly communicate their findings to the scientific community,” she said. “This, in turn, provides them with opportunities for earlier and broader feedback and a way to transparently demonstrate progress on a project. More importantly, the whole community benefits by having earlier access to research findings, which can accelerate the pace of discovery.”
The disclosures applied to every preprint paper are the publisher’s way of assuring this same awareness, she said. And preprints do need to be approached with some skepticism, as should peer-reviewed literature.
“The veracity of published papers is not always a given. An example is the 1998 vaccine paper [published in the Lancet] by Dr. Andrew Wakefield,” which launched the antivaccine movement. “But the answer to problems of reliability is to provide more information about the research and how it has been verified and evaluated, not less information. For example, confirmation bias can make it difficult to refute work that has been published. The current incentives for publishing negative results in a journal are not strong enough to reveal all of the information that could be useful to other researchers, but preprinting reduces the barrier to sharing negative results,” she said.
Swimming up the (main)stream
Universal peer-reviewed acceptance of preprints isn’t a done deal, Dr. Polka said. Journals are tussling with how to handle these papers. The Lancet clearly states that preprints don’t constitute prior publication and are welcome. The New England Journal of Medicine offers an uncontestable “no way.”
JAMA discourages submitting preprints, and will consider one only if the submitted version offers “meaningful new information” above what the preprint disseminated.
Cell Press has a slightly different take. They will consider papers previously posted on preprint services, but the policy applies only to the original submitted version of the paper. “We do not support posting of revisions that respond to editorial input and peer review or the final published version to preprint servers,” the policy notes.
In an interview, Deborah Sweet, PhD, the group’s vice president of editorial, elaborated on the policy. “In our view, one of the most important purposes of preprint posting is to gather feedback from the scientific community before a formal submission to a journal,” she said. “The ‘original submission’ term in our guidelines refers to the first version of the paper submitted to [Cell Press], which could include revisions made in response to community feedback on a preprint. After formal submission, we think it is most appropriate to incorporate and represent the value of the editorial and peer-review evaluation process in the final published journal article so that is clearly identifiable as the version of record.”
bioRxiv has made substantial inroads with dozens of other peer-reviewed journals. More than 100 – including a number of publications by EMBO Press and PLOS (Public Library of Science) – participate in bioRxiv’s B2J (BioRxiv-to-journal) direct-submission program.
With a few clicks, authors can transmit their bioRxiv manuscript files directly to these journals, without having to prepare separate submissions, Dr. Sweet said. Last year, Cell Press added two publications – Cell Reports and Structure – to the B2J program. “Once the paper is sent, it moves behind the scenes to the journal system and reappears as a formal submission,” she said. “In our process, before transferring the paper to the journal editors, authors have a chance to update the files (for example, to add a cover letter) and answer the standard questions that we ask, including ones about reviewer suggestions and exclusion requests. Once that step is done, the paper is handed over to the editorial team, and it’s ready to go for consideration in the same way as any other submission.”
Who’s reading?
Regardless of whether peer-review journals grant them legitimacy, preprints are getting a lot of views. A recent research letter, published in JAMA, looked at readership and online attention in 7,750 preprints posted from November 2013 to January 2017.
Primary author Stylianos Serghiou then selected 776 papers that had first appeared in bioRxiv, and matched them with 3,647 peer-reviewed articles lacking preprint exposure. He examined several publishing metrics for the papers, including views and downloads, citations in other sources, and Altmetric scores.
Altmetric tracks digital attention to scientific papers: Wikipedia citations, mentions in policy documents, blog discussions, and social media mentions including Facebook, Reddit, and Twitter. An Altmetric “attention score” of more than 20 corresponds to articles in the top 5% of readership, he said in an interview.
“Almost one in five of the bioRxiv preprints were getting these very high Almetric scores – much higher scores than articles that had no preprint posting,” Mr. Serghiou said in an interview.
Other findings include:
- The median number of preprint abstract views was 924, and the median number of PDF downloads was 321.
- In total, 18% of the preprints achieved an Altmetric score of more than 20.
- Of 7,750 preprints, 55% were accepted in a peer-reviewed publication within 24 months.
- Altmetric scores were significantly higher in articles in preprints (median 9.5 vs. 3.5).
The differences are probably related, at least in part, to the digital media savvy of preprint authors, Mr. Serghiou suggested. “We speculate that people who publish in bioRxiv may be more familiar with social media methods of making others aware of their work. They tend to be very good at using platforms like Twitter and Facebook to promote their results.”
Despite the high exposure scores, only 10% of bioRxiv articles get any posted comments or feedback – a key raison d’être for using a preprint service.
“Ten percent doesn’t sound like a very robust [feedback], but most journal articles get no comments whatsoever,” Dr. Inglis said. “And if they do, especially on the weekly magazines of science, comments may be from someone who has an ax to grind, or who doesn’t know much about the subject.”
What isn’t measured, in either volume or import, is the private communication a preprint engenders, Dr. Inglis said. “Feedback comes directly and privately to the author through email or at meetings or on the phone. We hear time and again that authors get hundreds of downloads after posting, and receive numerous contacts from colleagues who want to know more, to point out weaknesses, or request collaborations. These are the advantages we see from this potentially anxiety-provoking process of putting a manuscript out that has not been approved for publication. The entire purpose is to accelerate the speed of research by accelerating the speed of communication.”
Dr. Inglis, Dr. Sweet, and Dr. Polka are all employees of their respective companies. Dr. Viny and Mr. Serghiou both reported having no financial disclosures relevant to this article.
Like an upstart quick-draw challenging a grizzled gunslinger, preprint servers are muscling in on the once-exclusive territory of scientific journals.
These online venues sidestep the time-honored but lengthy peer-review process in favor of instant data dissemination. By directly posting unreviewed papers, authors escape the months-long drudgery of peer review, stake an immediate claim on new ideas, and connect instantly with like-minded scientists whose feedback can mold this new idea into a sound scientific contribution.
“The caveat, of course, is that it may be crap.”
That’s the unvarnished truth of preprint publishing, said John Inglis, PhD – and he should know. As the cofounder of Cold Spring Harbor Laboratory’s bioRxiv, the largest-to-date preprint server for the biological sciences, he gives equal billing to both the lofty and the low, and lets them soar or sink by their own merit.
And many of them do soar, Dr. Inglis said. Of the more than 20,000 papers published since bioRxiv’s modest beginning in 2013, slightly more than 60% have gone on to peer-reviewed publication. The four most prolific sources of bioRxiv preprints are the research powerhouses of Stanford, Cambridge, Oxford, and Harvard. The twitterverse is virtually awash with #bioRxiv tags, which alert bioRxiv’s 18,000 followers to new papers in any of 27 subject areas. “We gave up counting 2 years ago, when we reached 100,000,” Dr. Inglis said.
BioRxiv, pronounced “bioarchive,” may be the largest preprint server for the biological sciences, but it’s not the only one. The Center for Open Science has created a preprint server search engine, which lists 25 such servers, a number of them in the life sciences.
PeerJ Preprints also offers a home for unreviewed papers, accepting “drafts of an article, abstract, or poster that has not yet been peer reviewed for formal publication.” Authors can submit a draft, incomplete, or final version, which can be online within 24 hours.
The bioRxiv model is coming to medicine, too. A new preprint server – to be called medRxiv – is expected to launch later in 2018 and will accept a wide range of papers on health and medicine, including clinical trial results.
Brand new or rebrand?
Preprint – or at least the concept of it – is nothing new, Dr. Inglis said. It’s simply the extension into the digital space of something that has been happening for many decades in the physical space.
Scientists have always written drafts of their papers and sent them out to friends and colleagues for feedback before unveiling them publicly. In the early 1990s, UC Berkeley astrophysicist Joanne Cohn began emailing unreviewed physics papers to colleagues. Within a couple of years, physicist Paul Ginsparg, PhD, of Cornell University, created a central repository for these papers at the Los Alamos National Laboratory. This repository became aRxiv, a central component of communication in the physical sciences, and the progenitor of the preprint servers now in existence.
The biological sciences were far behind this curve of open sharing, Dr. Inglis said. “I think some biologists were always aware of aRxiv and intrigued by it, but most were unconvinced that the habits and behaviors of research biologists would support a similar process.”
The competition inherent in research biology was likely a large driver of that lag. “Biological experiments are complicated, it takes a long time for ideas to evolve and results to arrive, and people are possessive of their data and ideas. They have always shared information through conferences, but there was a lot of hesitation about making this information available in an uncontrolled way, beyond the audiences at those meetings,” he said.
[polldaddy:9970002]
Nature Publishing Group first floated the preprint notion among biologists in 2006, with Nature Precedings. It published more than 2,000 papers before folding, rather suddenly, in 2012. A publisher’s statement simply said that the effort was “unsustainable as originally conceived.”
Commentators suspected the model was a financial bust, and indeed, preprint servers aren’t money machines. BioRxiv, proudly not for profit, was founded with financial support from Cold Spring Harbor Laboratory and survives largely on private grants. In April 2017, it received a grant for an undisclosed amount from the Chan Zuckerberg Initiative, established by Facebook founder Mark Zuckerberg and his wife, Priscilla Chan.
Who’s minding the data?
The screening process at bioRxiv is minimal, Dr. Inglis said. An in-house staff checks each paper for obvious flaws, like plagiarism, irrelevance, unacceptable article type, and offensive language. Then they’re sent out to a committee of affiliate scientists, which confirms that the manuscript is a research paper and that it contains science, without judging the quality of that science. Papers aren’t edited before being posted online.
Each bioRxiv paper gets a DOI link, and appears with the following disclaimer detailing the risks inherent in reading “unrefereed” science: “Because [peer review] can be lengthy, authors use the bioRxiv service to make their manuscripts available as ‘preprints’ before peer review, allowing other scientists to see, discuss, and comment on the findings immediately. Readers should therefore be aware that articles on bioRxiv have not been finalized by authors, might contain errors, and report information that has not yet been accepted or endorsed in any way by the scientific or medical community.”
From biology to medicine
The bioRxiv team is poised to jump into a different pool now – medical science. Although the launch date isn’t firm yet, medRxiv will go live sometime very soon, Dr. Inglis said. It’s a proposed partnership between Cold Spring Harbor Laboratory, the Yale-based YODA Project (Yale University Open Data Access Project), and BMJ. The medRxiv papers, like those posted to bioRxiv, will be screened but not peer reviewed or scrutinized for trial design, methodology, or interpretation of results.
The benefits of medRxiv will be more rapid communication of research results, increased opportunities for collaboration, the sharing of hard-to-publish outputs like quality innovations in health care, and greater transparency of clinical trials data, Dr. Inglis said. Despite this, he expects the same kind of push-back bioRxiv initially encountered, at least in the beginning.
“I expect we will be turning the clock back 5 years and find a lot of people who think this is potentially a bad thing, a risk that poor information or misinformation is going to be disseminated to a wider audience, which is exactly what we heard about bioRxiv,” he said. “But we hope that when medRxiv launches, it will demonstrate the same kind of gradual acceptance as people get more and more familiar with the preprint platform.”
The founders intend to build into the server policies to mitigate the risk from medically relevant information that hasn’t been peer reviewed, such as not accepting case studies or editorials and opinion pieces, he added.
While many find the preprint disclaimer acceptable on papers that have no immediate clinical impact, there is concern about applying it to papers that discuss patient treatment.
Howard Bauchner, MD, JAMA’s editor in chief, addressed it in an editorial published in September 2017. Although not explicitly directed at bioRxiv, Dr. Bauchner took a firm stance against shortcutting the evaluation of evidence that is often years in the making.
“New interest in preprint servers in clinical medicine increases the likelihood of premature dissemination and public consumption of clinical research findings prior to rigorous evaluation and peer review,” Dr. Bauchner wrote. “For most articles, public consumption of research findings prior to peer review will have little influence on health, but for some articles, the effect could be devastating for some patients if the results made public prior to peer review are wrong or incorrectly interpreted.”
Dr. Bauchner did not overstate the potential influence of unvetted science, as a January 2018 bioRxiv study on CRISPR gene editing clearly demonstrated. The paper by Carsten Charlesworth, a doctoral student at Stanford (Calif.) University, found that up to 79% of humans could already be immune to Crispr-Cas9, the gene-editing protein derived from Staphylococcus aureus and S. pyogenes. More than science geeks were reading: The report initially sent CRISPR stocks tumbling.
Aaron D. Viny, MD, is in general a hesitant fan of bioRxiv’s preprint platform. But he raised an eyebrow when he learned about medRxiv.
“The only pressure that I can see in regulating these reports is social media,” said Dr. Viny, a hematologic oncologist at Memorial Sloan Kettering, in New York. “The fear is that it will be misused in two different realms. The most dangerous and worrisome, of course, is for patients using the data to influence their care plan, when the data haven’t been vetted appropriately. But secondarily, how could it influence the economics of clinical trials? There is no shortage of hedge fund managers in biotech. These data could misinform a consultant who might know the area in a way that artificially exploits early research data. Could that permit someone to submit disingenuous data to manipulate the stock of a given pharmaceutical company? I don’t know how you police that kind of thing.”
Who’s loving it – and why?
There are plenty of reasons to support a thriving preprint community, said Jessica Polka, PhD, director of ASAPbio, (Accelerating Science and Publication in biology), a group that bills itself as a scientist-driven initiative to promote the productive use of preprints in the life sciences.
“Preprinting complements traditional journal publishing by allowing researchers to rapidly communicate their findings to the scientific community,” she said. “This, in turn, provides them with opportunities for earlier and broader feedback and a way to transparently demonstrate progress on a project. More importantly, the whole community benefits by having earlier access to research findings, which can accelerate the pace of discovery.”
The disclosures applied to every preprint paper are the publisher’s way of assuring this same awareness, she said. And preprints do need to be approached with some skepticism, as should peer-reviewed literature.
“The veracity of published papers is not always a given. An example is the 1998 vaccine paper [published in the Lancet] by Dr. Andrew Wakefield,” which launched the antivaccine movement. “But the answer to problems of reliability is to provide more information about the research and how it has been verified and evaluated, not less information. For example, confirmation bias can make it difficult to refute work that has been published. The current incentives for publishing negative results in a journal are not strong enough to reveal all of the information that could be useful to other researchers, but preprinting reduces the barrier to sharing negative results,” she said.
Swimming up the (main)stream
Universal peer-reviewed acceptance of preprints isn’t a done deal, Dr. Polka said. Journals are tussling with how to handle these papers. The Lancet clearly states that preprints don’t constitute prior publication and are welcome. The New England Journal of Medicine offers an uncontestable “no way.”
JAMA discourages submitting preprints, and will consider one only if the submitted version offers “meaningful new information” above what the preprint disseminated.
Cell Press has a slightly different take. They will consider papers previously posted on preprint services, but the policy applies only to the original submitted version of the paper. “We do not support posting of revisions that respond to editorial input and peer review or the final published version to preprint servers,” the policy notes.
In an interview, Deborah Sweet, PhD, the group’s vice president of editorial, elaborated on the policy. “In our view, one of the most important purposes of preprint posting is to gather feedback from the scientific community before a formal submission to a journal,” she said. “The ‘original submission’ term in our guidelines refers to the first version of the paper submitted to [Cell Press], which could include revisions made in response to community feedback on a preprint. After formal submission, we think it is most appropriate to incorporate and represent the value of the editorial and peer-review evaluation process in the final published journal article so that is clearly identifiable as the version of record.”
bioRxiv has made substantial inroads with dozens of other peer-reviewed journals. More than 100 – including a number of publications by EMBO Press and PLOS (Public Library of Science) – participate in bioRxiv’s B2J (BioRxiv-to-journal) direct-submission program.
With a few clicks, authors can transmit their bioRxiv manuscript files directly to these journals, without having to prepare separate submissions, Dr. Sweet said. Last year, Cell Press added two publications – Cell Reports and Structure – to the B2J program. “Once the paper is sent, it moves behind the scenes to the journal system and reappears as a formal submission,” she said. “In our process, before transferring the paper to the journal editors, authors have a chance to update the files (for example, to add a cover letter) and answer the standard questions that we ask, including ones about reviewer suggestions and exclusion requests. Once that step is done, the paper is handed over to the editorial team, and it’s ready to go for consideration in the same way as any other submission.”
Who’s reading?
Regardless of whether peer-review journals grant them legitimacy, preprints are getting a lot of views. A recent research letter, published in JAMA, looked at readership and online attention in 7,750 preprints posted from November 2013 to January 2017.
Primary author Stylianos Serghiou then selected 776 papers that had first appeared in bioRxiv, and matched them with 3,647 peer-reviewed articles lacking preprint exposure. He examined several publishing metrics for the papers, including views and downloads, citations in other sources, and Altmetric scores.
Altmetric tracks digital attention to scientific papers: Wikipedia citations, mentions in policy documents, blog discussions, and social media mentions including Facebook, Reddit, and Twitter. An Altmetric “attention score” of more than 20 corresponds to articles in the top 5% of readership, he said in an interview.
“Almost one in five of the bioRxiv preprints were getting these very high Almetric scores – much higher scores than articles that had no preprint posting,” Mr. Serghiou said in an interview.
Other findings include:
- The median number of preprint abstract views was 924, and the median number of PDF downloads was 321.
- In total, 18% of the preprints achieved an Altmetric score of more than 20.
- Of 7,750 preprints, 55% were accepted in a peer-reviewed publication within 24 months.
- Altmetric scores were significantly higher in articles in preprints (median 9.5 vs. 3.5).
The differences are probably related, at least in part, to the digital media savvy of preprint authors, Mr. Serghiou suggested. “We speculate that people who publish in bioRxiv may be more familiar with social media methods of making others aware of their work. They tend to be very good at using platforms like Twitter and Facebook to promote their results.”
Despite the high exposure scores, only 10% of bioRxiv articles get any posted comments or feedback – a key raison d’être for using a preprint service.
“Ten percent doesn’t sound like a very robust [feedback], but most journal articles get no comments whatsoever,” Dr. Inglis said. “And if they do, especially on the weekly magazines of science, comments may be from someone who has an ax to grind, or who doesn’t know much about the subject.”
What isn’t measured, in either volume or import, is the private communication a preprint engenders, Dr. Inglis said. “Feedback comes directly and privately to the author through email or at meetings or on the phone. We hear time and again that authors get hundreds of downloads after posting, and receive numerous contacts from colleagues who want to know more, to point out weaknesses, or request collaborations. These are the advantages we see from this potentially anxiety-provoking process of putting a manuscript out that has not been approved for publication. The entire purpose is to accelerate the speed of research by accelerating the speed of communication.”
Dr. Inglis, Dr. Sweet, and Dr. Polka are all employees of their respective companies. Dr. Viny and Mr. Serghiou both reported having no financial disclosures relevant to this article.